Attention 机制最早于图像领域提出,而最近被引入了自然语言处理领域,在取得了良好的效果的同时,由于其可并行性,甚至有一举取代 RNN、LSTM 等 NLP 经典模型的趋势。
注意力机制
何为注意力?正如人类的注意力一样,例如看一篇文章,人的注意力往往会在图片上,然后对文章的标题、开头有一些注意,对文章内容可能就不那么关注。在 NLP 中处理句子中每个词也是如此,因为我们希望处理每个词的时候可以获得上下文信息,像 RNN 就是通过依次输入然后获得上文信息,但是这样每个词都是以同样的方式处理,而且越远可能信息就会保留的更少。所以注意力将整句话输入,得到整句话中每个词和当前词的相关程度,即为注意力,说明这些词与当前词关系密切,就可以更多的集成这些词的信息。

通常 Attention 会与传统的模型配合起来使用,但 Google 的一篇论文 Attention Is All You Need 中提出,正如其名,只需要注意力就可以完成传统模型所能完成的任务,从而摆脱传统模型对于长程依赖无能为力的问题并使得模型可以并行化,并基于此提出 Transformer 模型。
Transformer
Transformer 和传统模型一样为 Encoder-Decoder 结构,将输入序列映射为输出序列(seq2seq),每一时间步会将上一时间步的输出作为输入,得到输出。整体结构上相比于当前的其他模型并没有很大的变化。
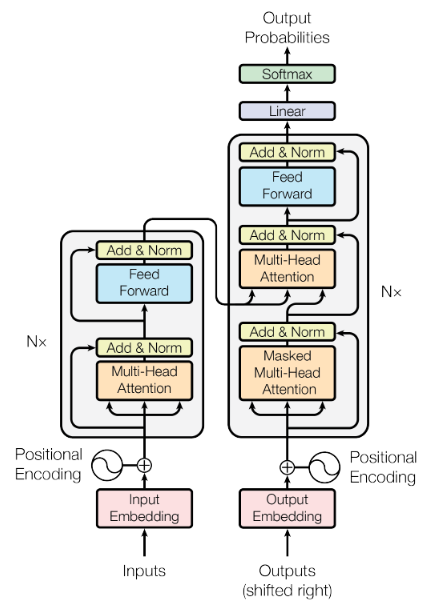
上图中左侧为 Encoder,右侧为 Decoder。在论文中 Encoder 和 Decoder 都被叠了 6 层。
Self-Attention
Self-Attention(自注意力)层是整个 Transformer 中最为关键的部分,它用来提取每个词的上下文信息。
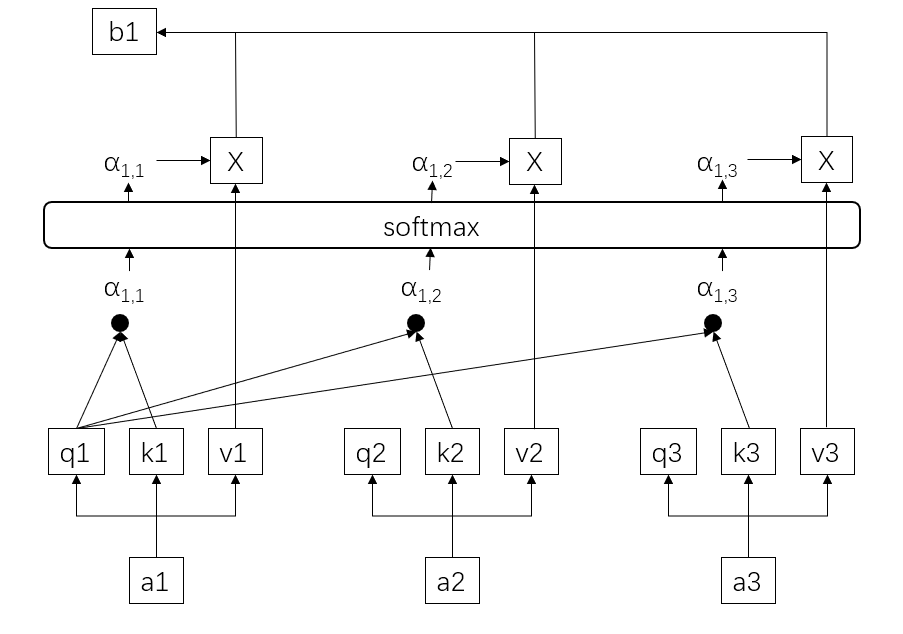
对于输入的每个词 \(a_i\),都会被用共享的可被训练的权重矩阵生成三个新的向量\(q_i\)、\(k_i\)、\(v_i\):
- Query:用来匹配其他词的 Key,以得到两个词之间的 attention
- Key:被其他词的 Query 匹配
- Value:表示当前词的值向量
这样,每个词的 \(Q\) 都会与其他所有词的 \(K\) 做点积,得到的值经过一层 softmax 都得到了当前词与其他所有词之间的 attention,以此为权重将所有词的 \(V\) 相加,就得到了当前词的上下文特征 \(b_i\),所以有
\[Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]实际做的时候多除以了一个 \(\sqrt{d_K}\),按照的作者的说法是因为 \(QK^T\) 的值会很大,如果直接进行 softmax 会导致梯度过小,所以用 \(\sqrt{d_K}\) 进行了一次缩放。
Multi-Head Attention
Multi-Head Attention(多头注意力)与之前的自注意力相同,只是在生成 \(Q\)、\(K\)、\(V\) 的时候,会生成多组,组的数量 \(H\) 可以让模型对每个词输出 \(H\) 个 Attention,从而可以获得更多的上下文信息。
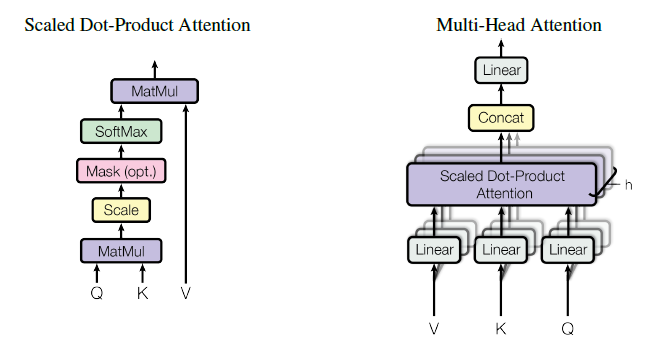
最后将所有的输出拼接起来成为一个向量输出。在 Transformer 模型中 \(H=8\),即有 8 个并行的注意力层,与此同时 \(d_k=d_v=d_{model}/h=64\)。每个层的参数量都变少了,所以与维度总数相同的单头注意力层计算量类似。
Positional Encoding
之前提到过,模型将整句句子作为整体一同作为输入,但这样都失去了句子中每个词的先后次序,为此 Transformer 中将每个词的位置也做了一次 encoding,与词本身的 encoding 相加之后作为最后的词向量。
Transformer 作者尝试了让模型自己学习 positional encoding 和选择确定的公式,但两者差别并不大,所以用了后者以减少可训练的参数数量
\[PE_{(pos,2i)}=sin(pos/10000^{2i/d_model}) \\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_model})\]其中 \(pos\) 为位置,\(i\) 为维度。
Feed-Forward Networks
在每个注意力层后都跟着一个全连接的前向反馈网络进行一次微调,该全连接层有两次线性变换,其中用 ReLU 作为激活函数。
\[FFN(x)=max(0,xW_1+b_1)W_2+b_2\]Transformer Stucture
几个层都了解过后,再让我们回来看看 Transformer 是如何把这些层糅合在一起的。
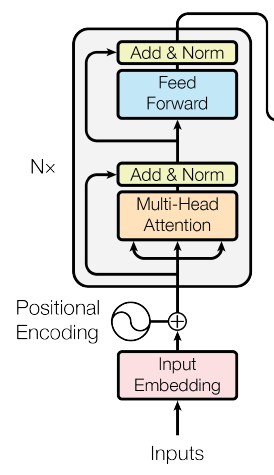
输入的词都会被进行一次 embedding 再与 positional encoding 得到的向量相加送入 encoder。每个 encoder 都由一个多头注意力层和一个前向反馈网络层组成。每个子层输出都会与输入相加再进行一次 Normalization(Add&Norm),即每个子层输出为 \(LayerNorm(x+SubLayer(x))\)。Transformer 会将此过程重复 6 次,也就是通过 6 次 encoder。
Normalization 用于将所有参数变成平均值为 0,方差为 1 的状态
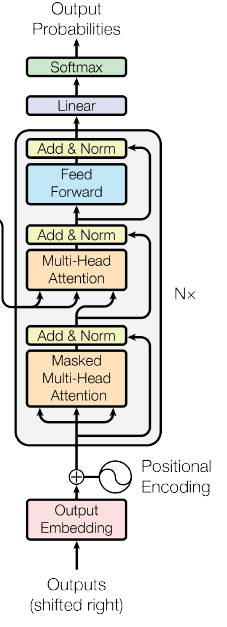
Decoder 部分同样为 6 层,并且有着与 encoder 相同输入,相同的多头注意力层和前馈网络层,相同的 Add&Norm,只是在其中又加了一层同时将 encoder stack 输出作为输入的注意力层。并且第一个注意力层变为 Masked 注意力层,将位于当前词之后的部分掩盖掉,以确保是从之前的句子内容中进行预测。在整个模型最后进行一次 Linear 变换和 softmax 就属于常规操作了。

从上图可以直观的看出,Transformer 首先并行的进行了多次对每个词的 encoding,结合了整句话的信息,然后利用 encoding 的结果和已经产生的输出一起预测下一个词,从 <BOS> 直到 <EOS>。
总结
Transformer 在整体结构上并没有做多大改变,关键在于处理时使用的层进行了改变,完全摒弃了 RNN 之流,利用注意力机制解决了传统方法中对于长程依赖问题和顺序性,对于训练速度也有了很好的改善。基于 Transformer 而诞生的 BERT 在当前更是有了一统 NLP 领域的趋势。